The Battle of the Compressors: Optimizing Spark Workloads with
By A Mystery Man Writer
Description
Hello!
Hope you’re having a wonderful time working with challenging issues around Data and Data Engineering. In this article let’s look at the different compression algorithms Apache Spark offers…

The Battle of the Compressors: Optimizing Spark Workloads with ZStd, Snappy and More for Parquet, by Siraj
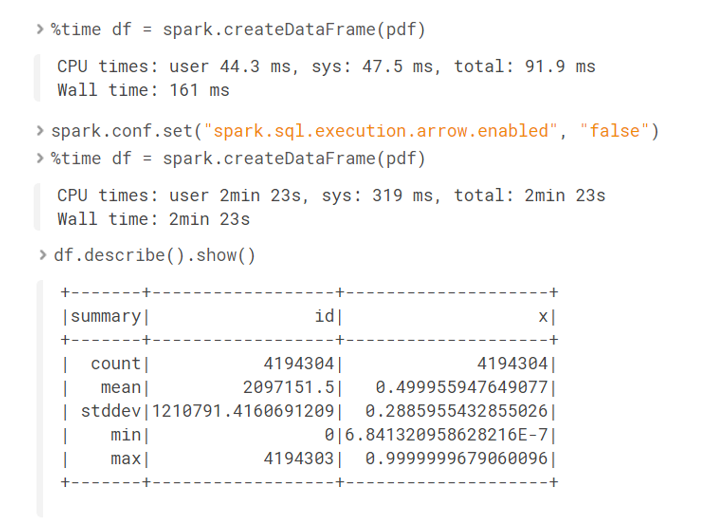
A gentle introduction to Apache Arrow with Apache Spark and Pandas, by Antonio Cachuan
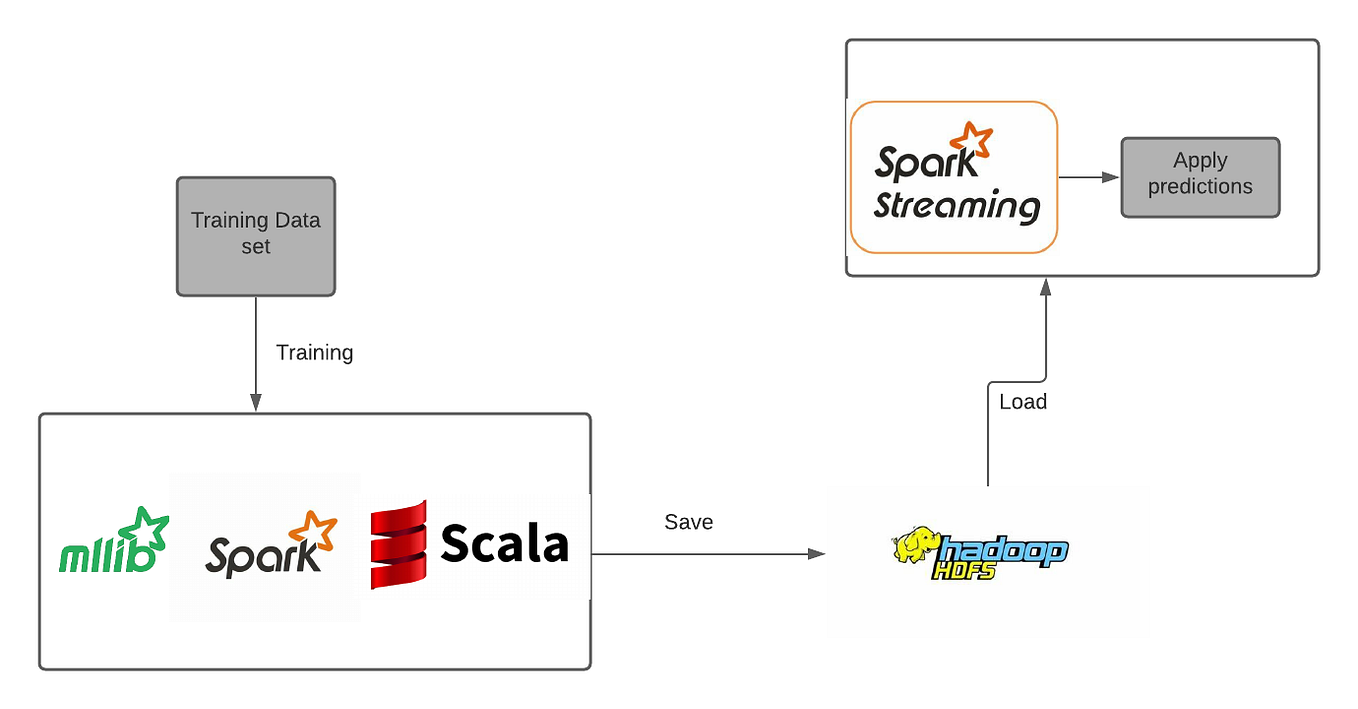
Spark catalyst optimizer and query optimization, by krishnaprasad k

A gentle introduction to Apache Arrow with Apache Spark and Pandas, by Antonio Cachuan

Running Peta-Scale Spark Jobs on Object Storage Using S3 Select, by Frank Wessels
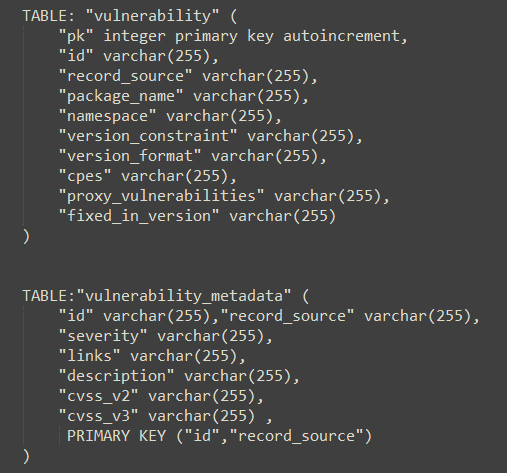
Picking the right compression for high volume data transfer, by Murali Suraparaju

PyCon Lithuania on LinkedIn: #pyconlt2024 #apachespark #apacheiceberg
Spark it up a notch II. Nitty-gritty details on pyspark…, by Jyotsna Parthasarathy

Load Data using EMR Spark with Apache Iceberg, by Vishal Khondre
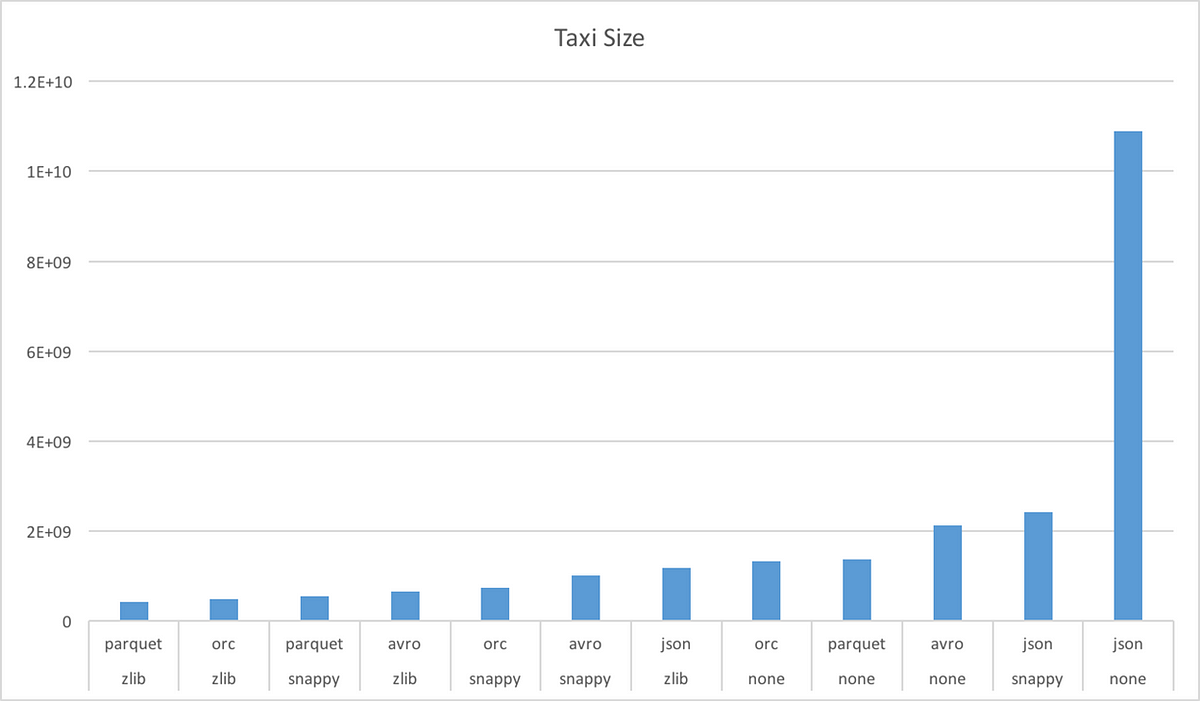
Avro vs Parquet. Let's talk about the difference between…, by Park Sehun

Under the hood of Spark performance, or why query compilation matters, by Victor Zaytsev, Criteo R&D Blog

Load Data using EMR Spark with Apache Iceberg, by Vishal Khondre
from
per adult (price varies by group size)


:max_bytes(150000):strip_icc()/focused-female-photographer-using-digital-camera-at-photo-shoot-in-studio-928146900-5c928fe846e0fb00010ae87a.jpg)


